I worked on the following projects.
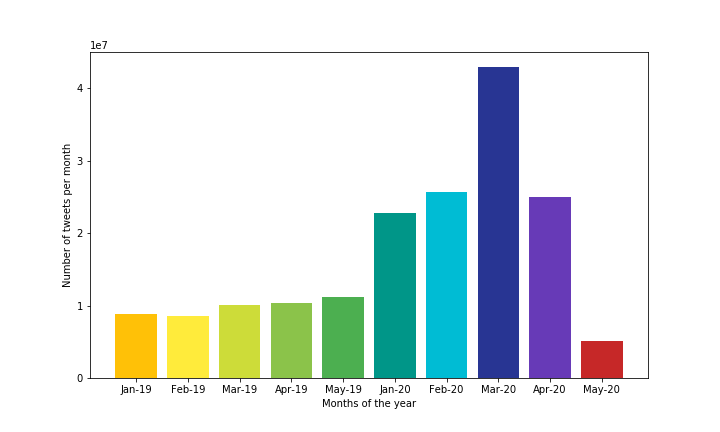
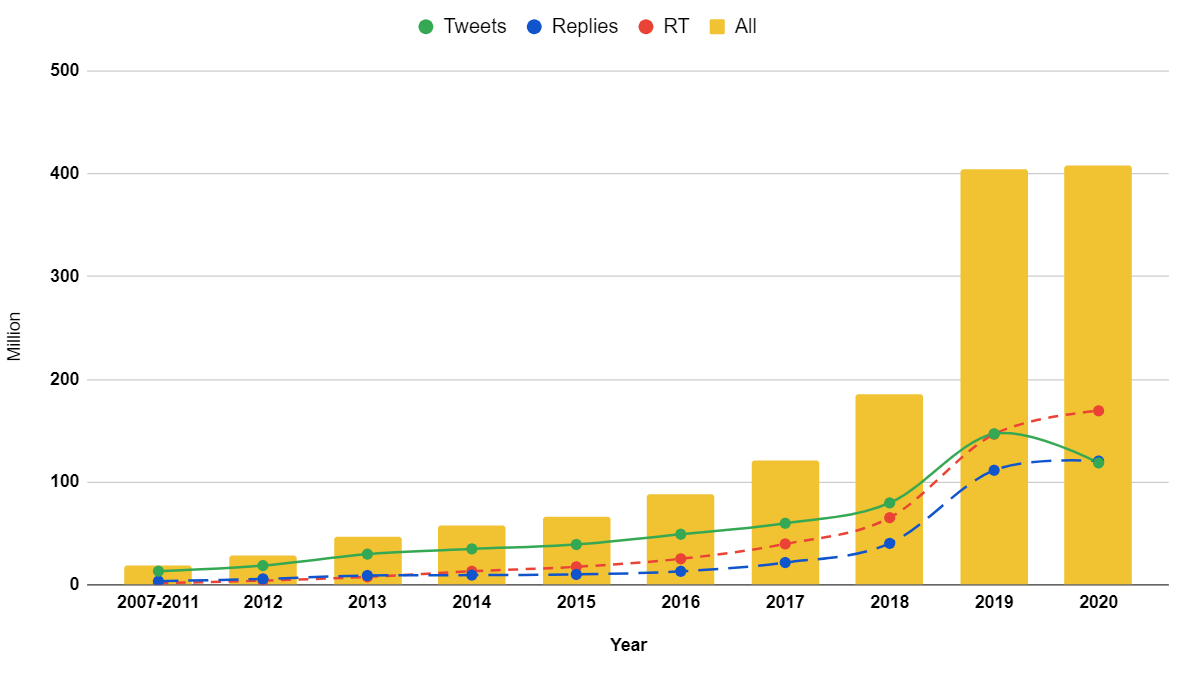
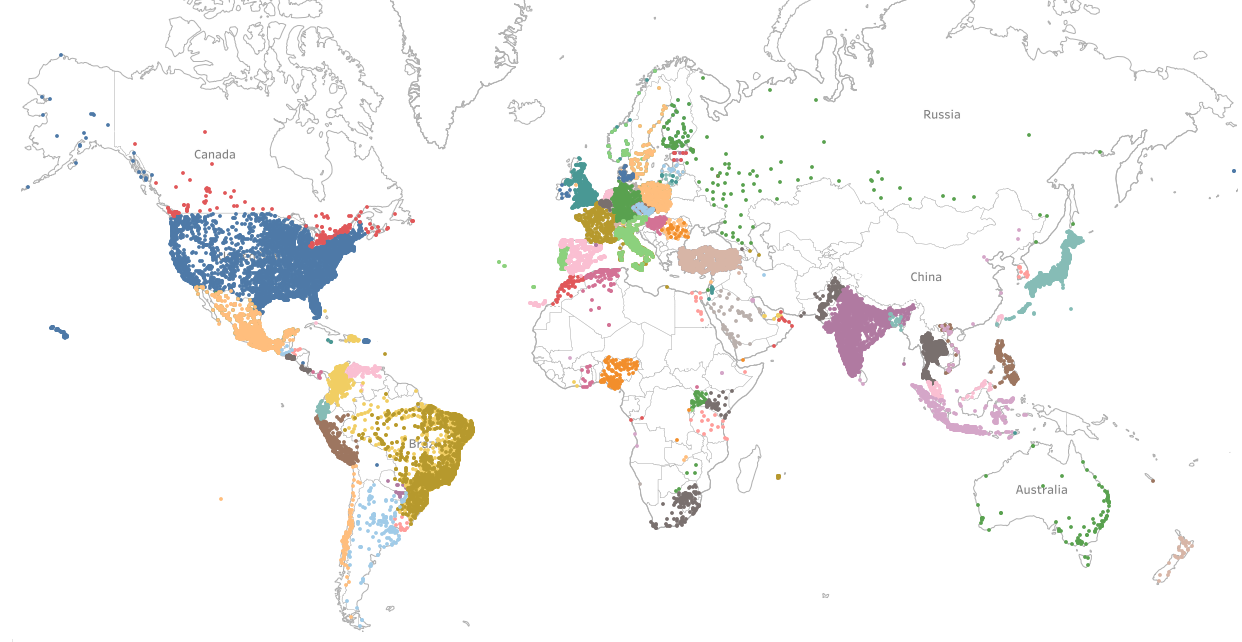
1. Mega-COV: A Billion-Scale Dataset of 100+ Languages for COVID-19
We describe Mega-COV, a billion-scale dataset from Twitter for studying COVID-19. The dataset is diverse (covers 268 countries), longitudinal (goes as back as 2007), multilingual (comes in 100+ languages), and has a significant number of location-tagged tweets (∼ 169M tweets). We also develop and release a powerful model (acc=94%) for teasing apart messages related to the pandemic from those that are not. Our data and models can be useful for studying various phenomena related to the pandemic, and accelerating viable solutions to associated problems. Our data and models are publicly available for research.
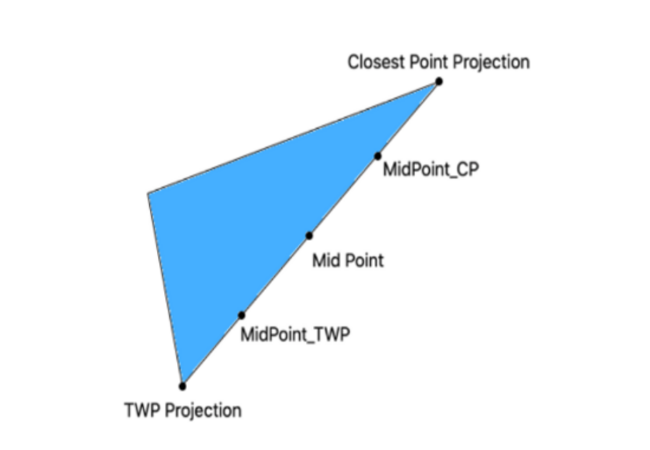
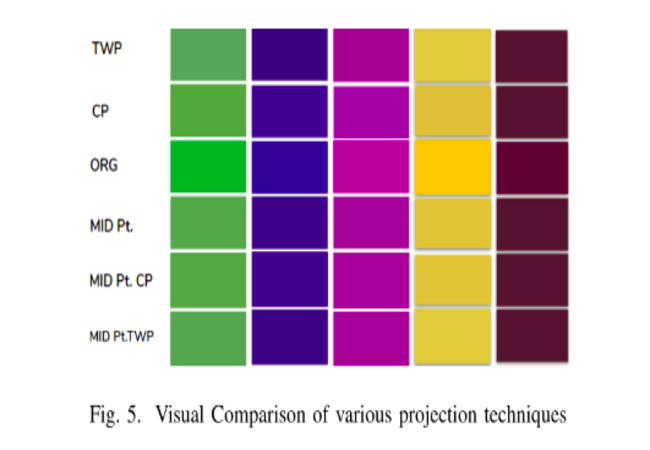
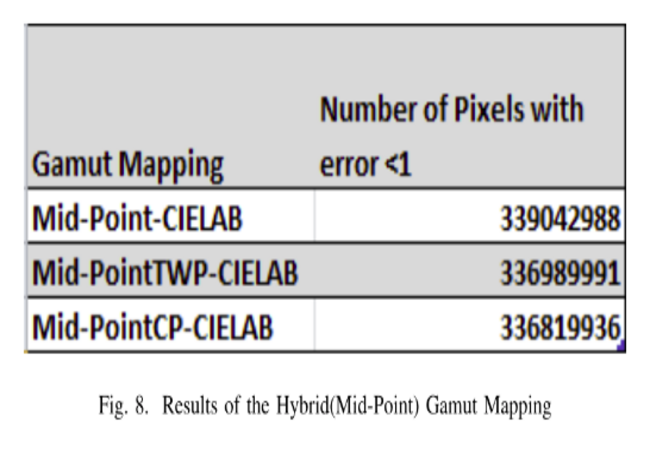
2. Gamut Mapping for Tone Mapping Operations
Gamut Mapping is a process to map colors from a higher gamut range to a lower gamut range or vice versa. To View UHD content in HD Displays we need to map the colors from BT2020 to BT709 and this can be done any colorspace. In this project We tried to improve the Mapping of colors from BT2020-> BT709 using mid-point algorithm, between closes point and towards white point.
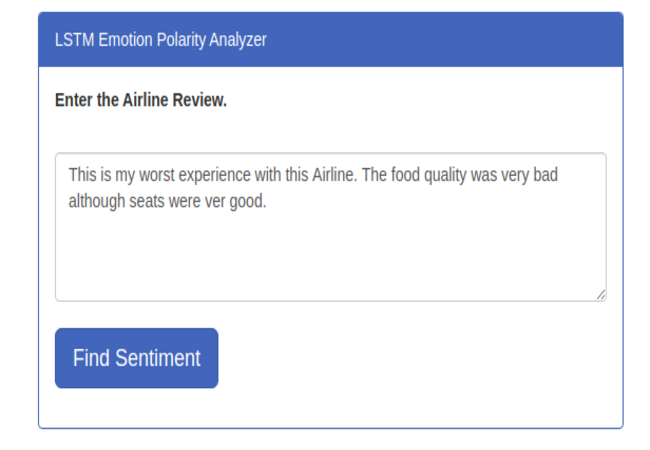
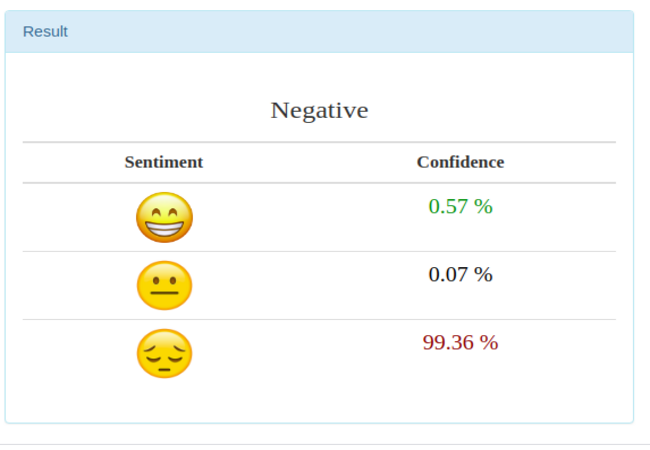
3. Emotional Polarity Classifier
The study of extracted information to identify reactions, attitudes, context and emotions.As one of the applications of text mining, sentiment analysis exposes the attitudes in the mined text. It is based on word polarities, it takes into account positive or negative words and neutral words are dismissed. Sentiment analysis is done based on lexicons. A lexicon in simpler terms is a vocabulary , say the English lexicon.In this context, a lexicon is a selection of words with the two polarities that can be used as a metric in sentiment analysis.